ComfyUI 是一款专注于 AI 绘图与图像生成的用户界面工具,为用户提供便捷且强大的功能支持。以下是有关 ComfyUI 官网及其官方资源的详细信息,帮助你更好地掌握和使用这一工具。
ComfyUI 官网
ComfyUI 官网是获取官方信息的最佳途径,包括最新版本、更新日志、安装指南和使用教程。通过官网,你可以获得权威、准确且及时的资讯,确保你的使用体验始终与最新进展保持同步。
- 官网链接:ComfyUI 官网
ComfyUI 官方资源
1. 官方文档
ComfyUI 提供详尽的使用文档,覆盖从安装到高级功能的全方位指南。尽管文档尚在完善中,你也可以访问 comfyui-wiki.com,一个致力于构建更全面资源的平台。
- 文档链接:ComfyUI 官方文档
2. 社区论坛
ComfyUI 的社区论坛聚集了大量用户与开发者,大家在此交流经验、分享创作、解决问题。这是一个友好且高效的学习与成长环境。
3. GitHub 仓库
ComfyUI 的源代码托管于 GitHub,开发者可以在这里查看项目代码、提交问题、贡献代码。GitHub 仓库也是了解项目动态和参与开发的重要渠道。
- GitHub 链接:ComfyUI 官方 GitHub 仓库
4. 官方社群
ComfyUI 官方社群是一个开放的交流平台,用户可以直接与其他爱好者和开发者互动,获取实时支持与建议。
- Discord 链接:ComfyUI 官方社群
5. 官方博客
通过 ComfyUI 官方博客,你可以获取最新新闻、功能更新和实用教程。这是深入了解工具进展的绝佳途径。
- 博客链接:ComfyUI 官方博客
常见问题解答(FAQ)
1. 什么是 ComfyUI?
ComfyUI 是一款专为 AI 绘图与图像生成设计的用户界面工具,旨在为用户提供丰富的创作资源与支持。
2. 如何访问 ComfyUI 官网?
你可以直接访问 ComfyUI 官网,以获取最新版本和官方资讯。
3. ComfyUI 提供哪些官方资源?
ComfyUI 提供了官方文档、社区论坛、GitHub 仓库、社群和博客等多种资源,全面覆盖用户的学习与使用需求。
为何要学习 ComfyUI?
在 AI 生图领域,有非常多的产品,比如 Midjourney,Stability AI 等等。为何要学习 ComfyUI 呢?
Midjourney VS ComfyUI
在回答这个问题之前,我觉得有必要介绍下目前市面上的各种 AI 生图产品,或者是 AI 生视频产品。在我的眼里,他们主要分成两大类:
- 模型与产品融合的产品,比如 Midjourney,Stability AI 等等。
- 模型与产品分离的产品,比如 SD Web UI、ComfyUI 等等。
这两类产品的优劣势如下:
| 融合产品(如 Midjourney,Stability AI 等) | 分离产品(如 SD WebUI,ComfyUI 等) | |
|---|---|---|
| 学习成本 | 低,产品一般对 UX 进行优化,且会配套各种教程。 | 高,产品一般多为开源产品,涉及多个开发者。UX 可能没有优化,且缺少教程。 |
| 迁移成本 | 高,当你切换一个产品时,需要重新学习产品的使用方法,同时还需要重新学习与模型相关的知识。 | 低,只需要重新学习模型相关的知识。 |
| 自由度 | 低,产品一般都是封闭的,你只能使用产品提供的功能。 | 高,产品一般都是开源的,你可以自由地修改产品,甚至可以自己开发产品。 |
| 费用 | 高,一般没有本地运行版本,都需要付费。 | 中,一般都会提供本地版本,如果你使用的是本地版就不需要付费,但你可能需要购置 GPU。 |
不难发现,这两类产品没有哪类产品拥有绝对的优势。选择哪款产品,完全取决于你的需求。
如果你只是当成娱乐,想要时不时制作一些图片或视频,那么,我推荐你选择融合产品。 因为它的学习成本低,你可以很快地学会如何使用,而且它的产品功能也比较完善,你可以很快地制作出一些图片或视频。
但如果你是设计师,或者你想靠 AI 这个新的技术赚钱,那么,我推荐你选择分离产品。 为什么呢?我觉得很多人选择学习何种软件时,很容易忽略两个原因。
首先是迁移成本。
如果我们选择学习第一种融合产品,那就意味着我们在学习软件的同时,还会跟模型绑定。拿 Midjourney 为例,当你学习 Midjourney 的时候,你需要学习软件如何使用,同时还要学习如何更好地使用模型,即如何写好 prompt。同时,它的产品功能也跟模型融合得比较深,有些功能是它这个模型特有的,当你学会后,你就只能在 Midjourney 上使用,而不能在其他产品上使用。
这会导致了一个非常高的学习迁移成本。当你想要更换产品的时候,你需要重新学习新产品的使用方法,同时还需要重新学习与模型相关的知识。
如果这个行业发展的速度比较慢的话,这个成本还可以接受(因为你有足够的时间去学习)。但是,现在 AI 行业发展非常快,每个月都会有新的产品,亦或者新的模型出现。你很难有时间去学习每一个产品。举个实际的例子,如果你选择学习融合产品,意味着:
- 当你看到 AI 能通过输入文字的方式生成图片,你可能会去学习 Midjourney,Stability AI,甚至 Adobe 的 AI 产品。
- 然后你又发现好像又有新的产品可以通过画图的方式生成图片,你可能又会去学习 Krea。
- 接着你发现 AI 还能生成视频,你又跑去学习 Runway、Pika。
最后你会发现,你好像学会了一堆软件,但又好像什么都没学会。因为每一款软件你都需要付出足够长的时间,才有可能真正学会,纯粹探索性的学习是不会有任何的积累(除非你只想娱乐一下)。
而学习分离产品,则能大大地降低这个迁移成本。当有一个新的模型出现时,你只需要切换模型就好了,而不需要重新学习产品的使用方法。比如,你学会了类似 SD WebUI 或者 ComfyUI 这类产品,你学会了如何文生图,当你需要通过画图的方式生成图片,你也只需要切换一些模型,或者在产品里操作一下就能实现与 Krea 类似的效果。
另一个关键是自由度。
我一直有这样的一个观点:AI 不会淘汰人类,但它会淘汰不会使用它们的人类。
你如果想要从 AI 这波浪潮里脱颖而出,你就需要学会如何使用 AI。而且不是单纯地使用 AI。你还需要学会如何调整 AI,从而让它切合你的工作流,甚至改造你的工作流。
因为它的自由度高,你可以自由地修改产品,甚至可以自己开发产品。这意味着你可以将产品与你的工作流结合,从而提高你的工作效率,甚至改造你的工作流。
SD Web UI VS ComfyUI
那市面上也有很多分离型产品,为何选择 ComfyUI?
我们先来简单看看 SD Web UI 和 ComfyUI 的 UI 界面,你应该就能知道它们的区别了。
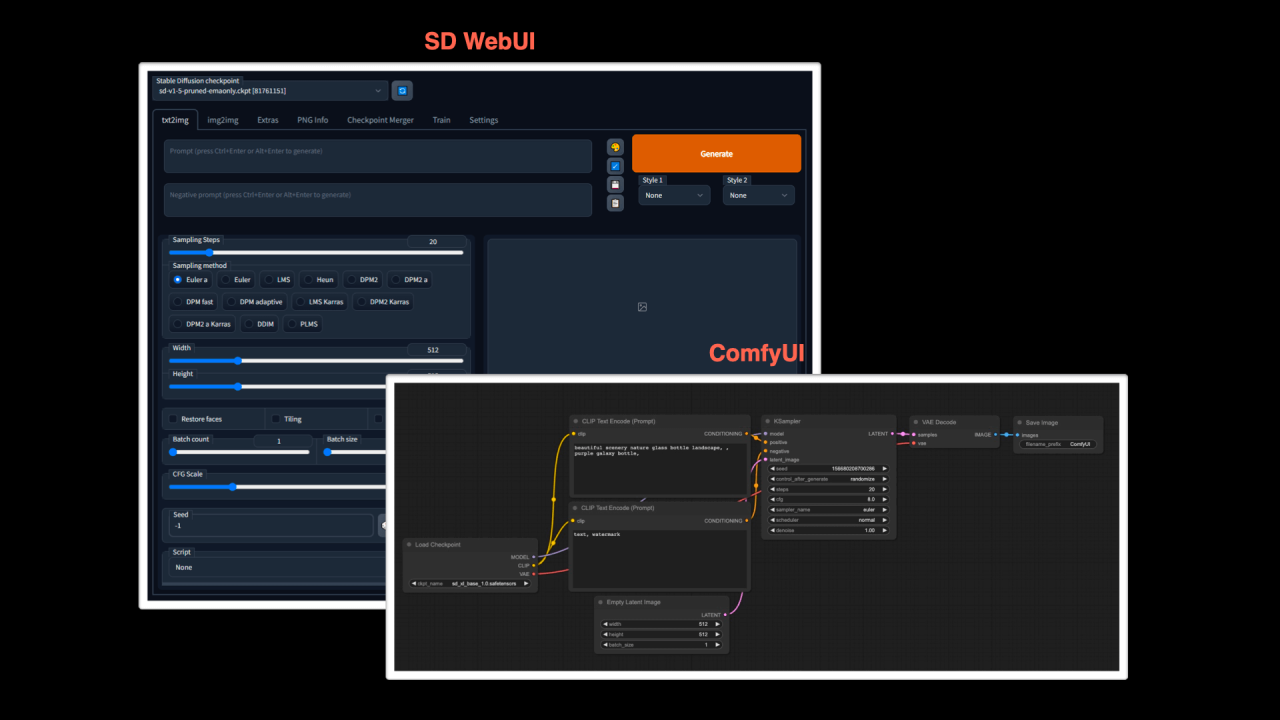
从上图中可以看到,SD WebUI 的 UI 更像是我们传统使用的产品,有很多输入框,还有多个按钮。而 ComfyUI 的 UI 界面则非常复杂,除了输入框,还有很多一块块的东西,并且还有很多复杂的连线。
的确,从学习成本来看,ComfyUI 的学习成本会比 SD WebUI 高。但是这种连线其实并不复杂,你可以这么理解:
- 这些小的方块跟 SD WebUI 的输入框和按钮是一样的,都是对参数进行配置。
- 连线有点像在搭建一个自动化的工作流,从左到右依次运行。
- 从功能的角度看,其实两个产品截图所提供的功能是一样的,只是 ComfyUI 变成了这种连线的方式。
这种方式有很什么好处了?我们一起来看看这两个用 ComfyUI 搭建的工作流:
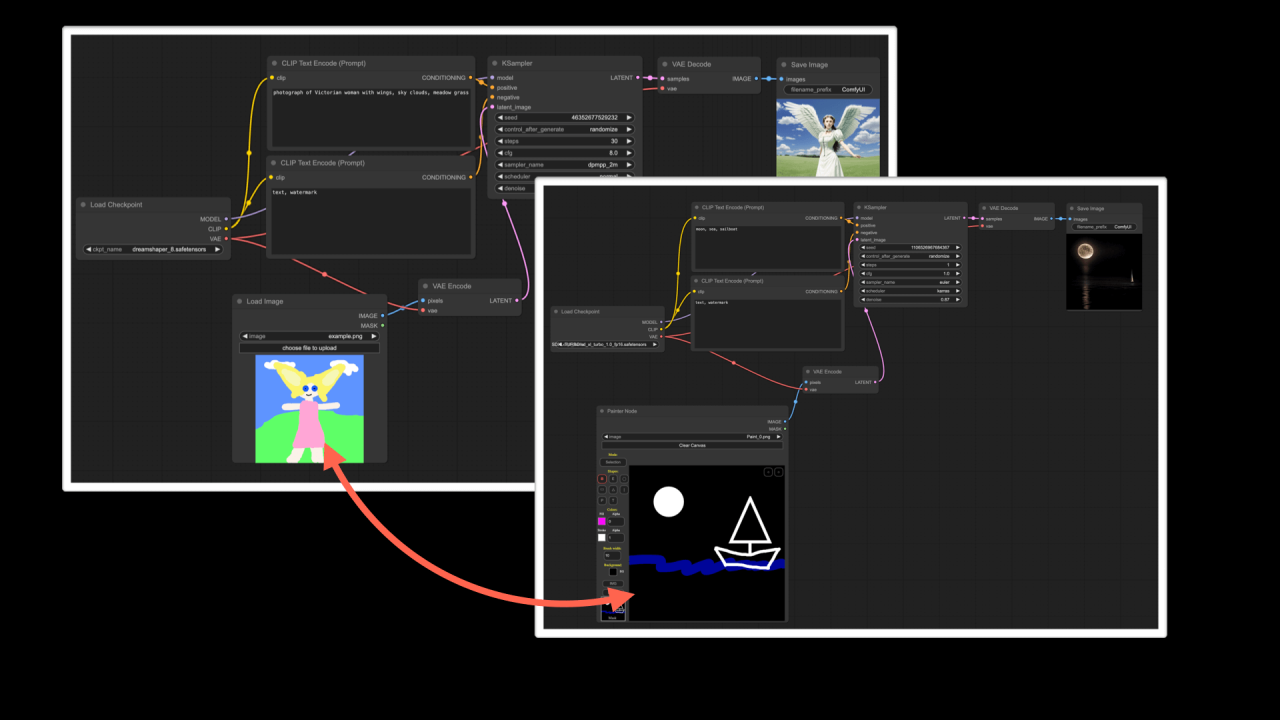
对比两个工作流,你会发现它只是有一个节点不一样,一个是直接加载图片,一个是通过画板绘制图片。这样就实现了两个不同的功能(一个是导入图片生图,一个是绘图生图)。这就意味着,你可以通过改变节点的方式来改变工作流,从而实现不同的功能。这样做有两个好处:
- 你可以根据自己的需求搭建适合自己的工作流,而不需要依赖开发者。
- 你也可以根据自己的需求,去开发并改造某个节点。
所以,选择 ComfyUI 最核心的原因就在于它的自由和拓展。那这就意味着你可以自己调整 ComfyUI 从而让它切合你的工作流,甚至改造你的工作流。
在现在这种 AI 发展如此迅猛的时代,我认为保持灵活才是最重要的。
如果你看各种对比评测,还会发现 ComfyUI 在性能上会比 SD WebUI 更好,但在能力的覆盖上会比 SD WebUI 要差,比如 ComfyUI 的 Inpainting 的编辑器就比 SD WebUI 的编辑器要差。但是,这些都不是问题,这些问题未来会依托开源生态逐步完善,或者说互有优势。但是我认为 SD WebUI 不进行非常大的改变的情况下,是无法实现 ComfyUI 那样的自由度的。
ComfyUI 官网及其官方资源为用户提供了完整的支持体系,无论你是初学者还是资深用户,都能在这里找到所需信息和帮助。通过这些资源,你可以充分发挥 ComfyUI 的功能,为你的 AI 绘图与图像生成创作提供助力。
目前安装 ComfyUI 的方法有以下两种,你可以根据自己的需求选择一种:
- 安装到本地:将 ComfyUI 安装在自己的电脑中,这样你可以在本地运行 ComfyUI。这种方式基本是 0 成本。但如果你的电脑 GPU 配置相对较差,有可能生图的速度会比较慢。
- 安装到云端:将 ComfyUI 安装在云端,这样的好处是云端配置相对较高,生成图片的速度会更快,但是需要一定的费用。
本章节会主要介绍如何在本地安装 ComfyUI,如果你想在云端安装,可以跳到 云端安装。
本地安装方法
命令行安装
本地安装有两种方法。第一种方法是普适性最强的方法 —— 命令行安装,且安装后二次遇到问题的概率相对较低。但是对于不熟悉命令行以及代码的用户来说,可能会有一定的门槛。所以本篇教程,主要是介绍这种方法。如果你在安装的过程中遇到问题,欢迎加入我们的 Discord(opens in a new tab) 交流群,我们会尽力帮助你。
另外,ComfyUI 的源码地址在 这里(opens in a new tab),安装方法写在了 Readme 中。你也可以按照 Readme 文档进行操作,并不一定要参照我的教程。
安装包安装
第二种方法是安装包安装。这种方法安装比较简单,下载就能用,目前我推荐两个安装包:
① ComfyUI 的官方安装包: 需要注意,目前仅支持 Windows 系统,且显卡必须是 Nivida。下载地址是这里(opens in a new tab),你只想需要下载最新的版本,解压就能使用。
② Comflowy 本地版: 相对于 ComfyUI 安装包,我更推荐你安装我们开发的全新开源 ComfyUI 产品 ComflowySpace 😎。这是一款基于 ComfyUI 二次开发的产品,使用功能上与 ComfyUI 一致。但我们对其进行了很多优化:
- 支持 Mac 系统。
- 支持 ComfyUI 没有的模板功能,可以一键使用本教程中提供的所有模板。
- 优化了非常多 ComfyUI 的体验问题,使用起来更方便和简单。完整介绍可以查看这里,以及 Comflowy 和 ComfyUI 的区别可以查看这篇文章。
欢迎各位下载使用,下载地址在这里(opens in a new tab)。
命令行安装步骤
第一步,安装 pytorch
如果你已经安装过 SD WebUI,那你可以跳到第二步。
首先你需要打开系统 Terminal,一般可以通过系统搜索即可找到。
Mac 和 Windows 上是长这样的。Windows 上因为版本不同,有可能跟我的截图不一样,只要名字对就可以了:

然后打开 Terminal,不管是什么系统,你应该都会看到类似的界面,可能 UI 颜色不一样,但一定是一串字符后有一个闪烁的光标:
此时不同的系统需要输入不同的命令。
Windows 用户我建议你在有 NVIDIA 显卡的电脑上使用。
下载 Miniconda3
第一步输入以下命令:
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe -o miniconda.exe安装 Miniconda3
下载完后,继续输入以下代码,安装 Miniconda3:
start /wait "" miniconda.exe /S安装 pytorch
安装 pytorch 的 nightly 版本即可。输入以下命令:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121
第二步,下载 ComfyUI
此步需要你将 ComfyUI 代码拉到本地。如果你会 Git 请在 Terminal 运行以下代码,即可完成此步骤:
git clone https://github.com/comfyanonymous/ComfyUI如果你不会用 Git,我推荐你使用 Github 的客户端(opens in a new tab) 拉代码,这是更简单的方式。
下载 Github Desktop 并安装
下载并安装好 Github Desktop 后,打开该应用。
打开 ComfyUI 项目 & 下载
然后打开 ComfyUI 的 Github 页面(opens in a new tab),点击右上角的绿色按钮(下图 ①),并点击菜单里的「Open with GitHub Desktop」(下图 ②),此时浏览器会弹出你是否要打开 GitHub Desktop,点击「是」。
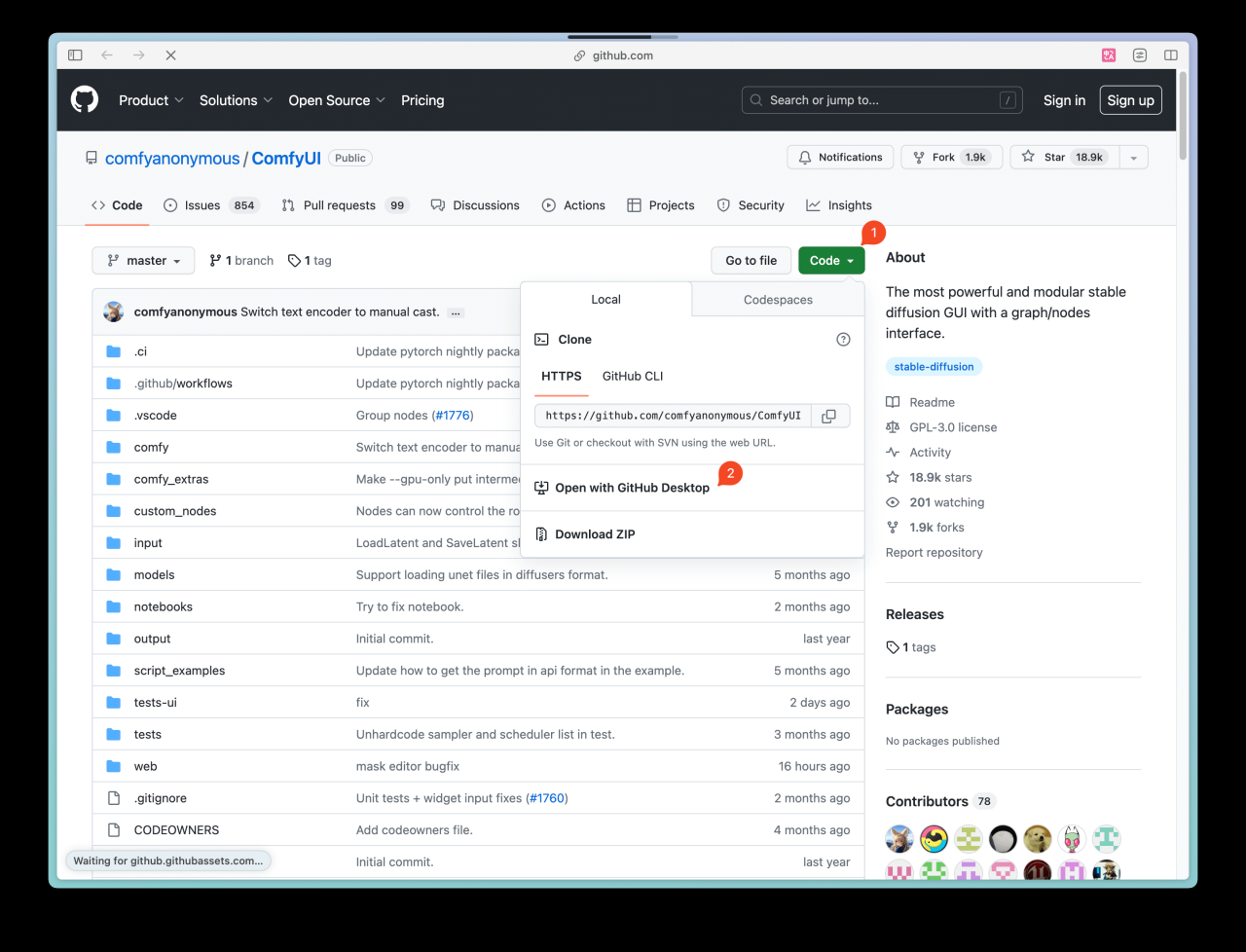
完成下载
接着 GitHub Desktop 会让你选择一个保存位置,你可以按需调整,然后点击确定。Github Desktop 会同步云端的代码到本地,如果你看到下方这样的界面,这就意味着你已经完成了代码同步。
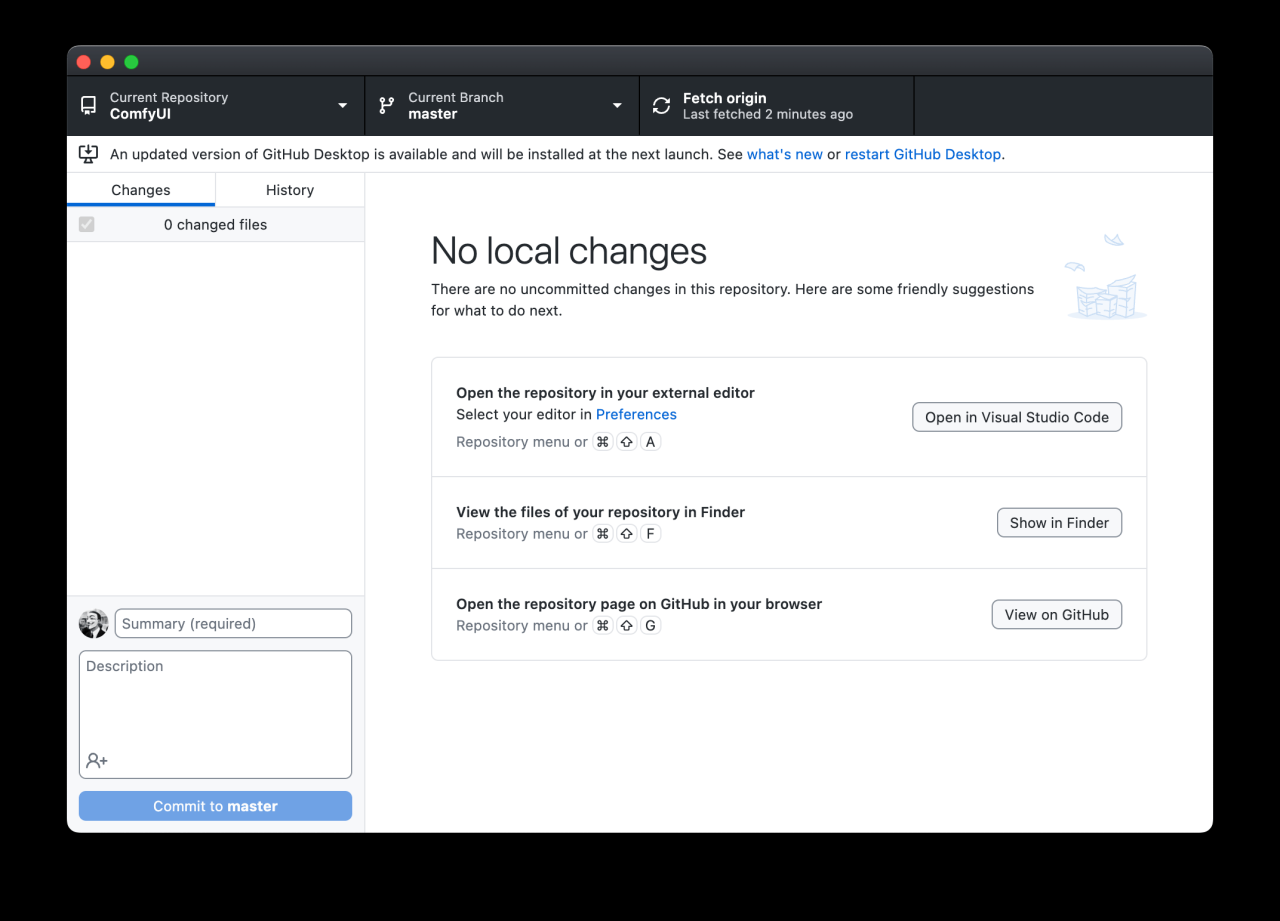
第三步,安装依赖
下载好代码后,需要安装依赖。有两种方法安装依赖。
如果你安装过 Visual Studio Code(opens in a new tab),那你只需要:
打开项目文件夹
在 Github Desktop 上点击「Open in Visual Studio Code」按钮。此时 VS Code 会打开。
打开 VS Code Terminal
接着你需要点击 VS Code 右上角的第二个 icon,然后你会在软件底部看到一个类似你之前在 Terminal 里看到的命令输入界面。
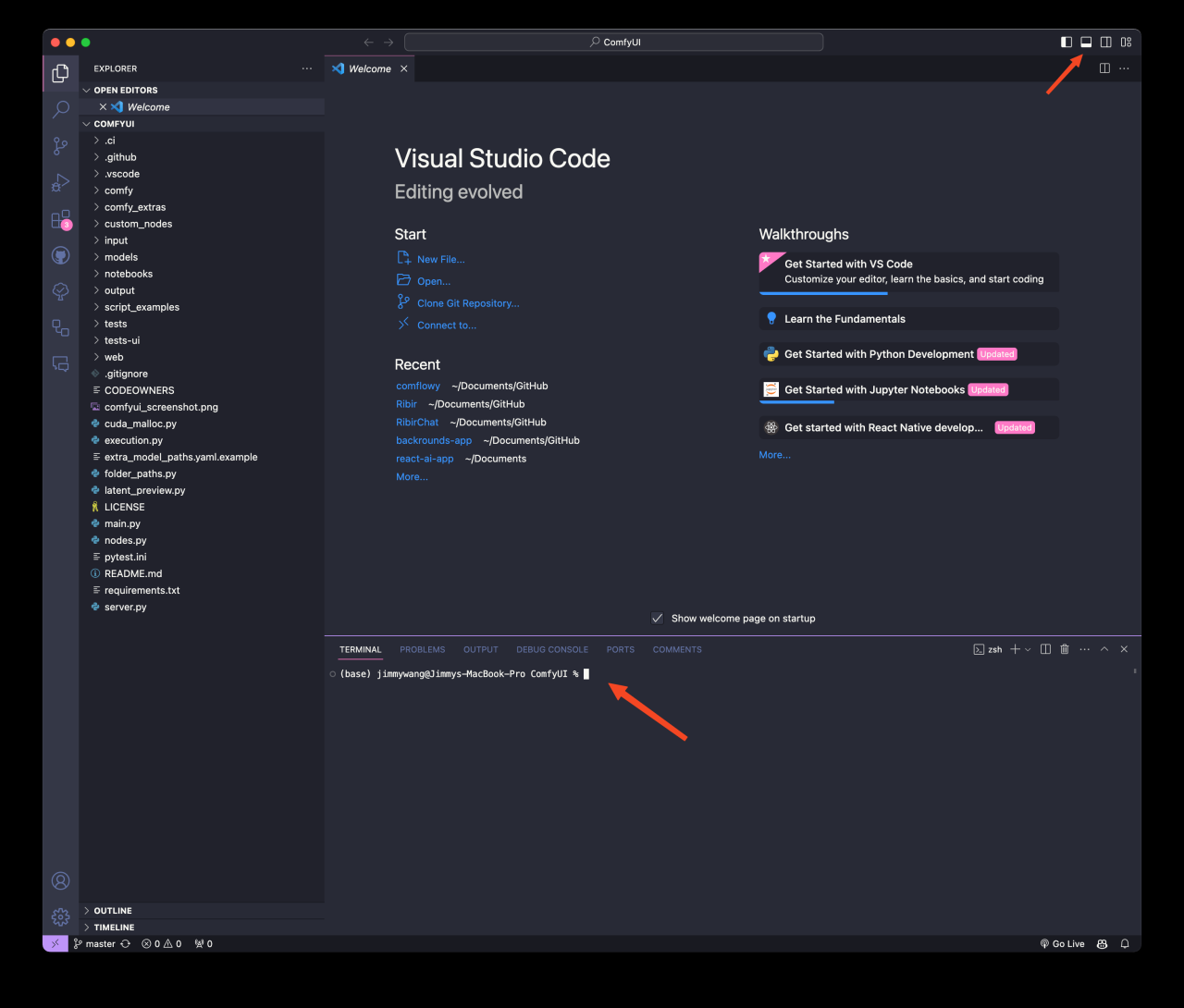
输入命令
最后一步你需要在底部 Terminal 输入以下命令,并点击回车:
# 如果遇到网络问题看后面的 Q&Apip install -r requirements.txt你有可能会遇到如 pip 安装的报错,那此时你可以尝试下 pip3:
pip3 install -r requirements.txt
不管使用哪种方法,你应该都会在最后看到「Successfully installed XXXXX」这就意味着你完成了安装。另外如果你遇到其他问题,可以查看本章最后的 Q&A。
第四步,启动服务
不管你在上一步是用 VS Code 运行,还是在 Terminal 里运行,你都可以继续输入以下代码:
python main.py这一步,如果你想让 ComfyUI 运行得更快,可以输入以下代码:
python main.py --force-fp16另外,如果你遇到类似上一步的报错问题,可以尝试用 python3:
python3 main.py当你看到「To see the GUI go to: http://127.0.0.1:8188」,(opens in a new tab) 就意味着你已经完成了 ComfyUI 的安装,并成功运行。此时你只需要在浏览器里复制黏贴下方地址即可:
http://127.0.0.1:8188/ 你应该能看到以下界面。恭喜你,ComfyUI 已经安装好了。但此时还没法运行 Stable DIffusion 生图。你还需要下载关键的模型,在下一章我会教大家如何下载并安装所需的模型。
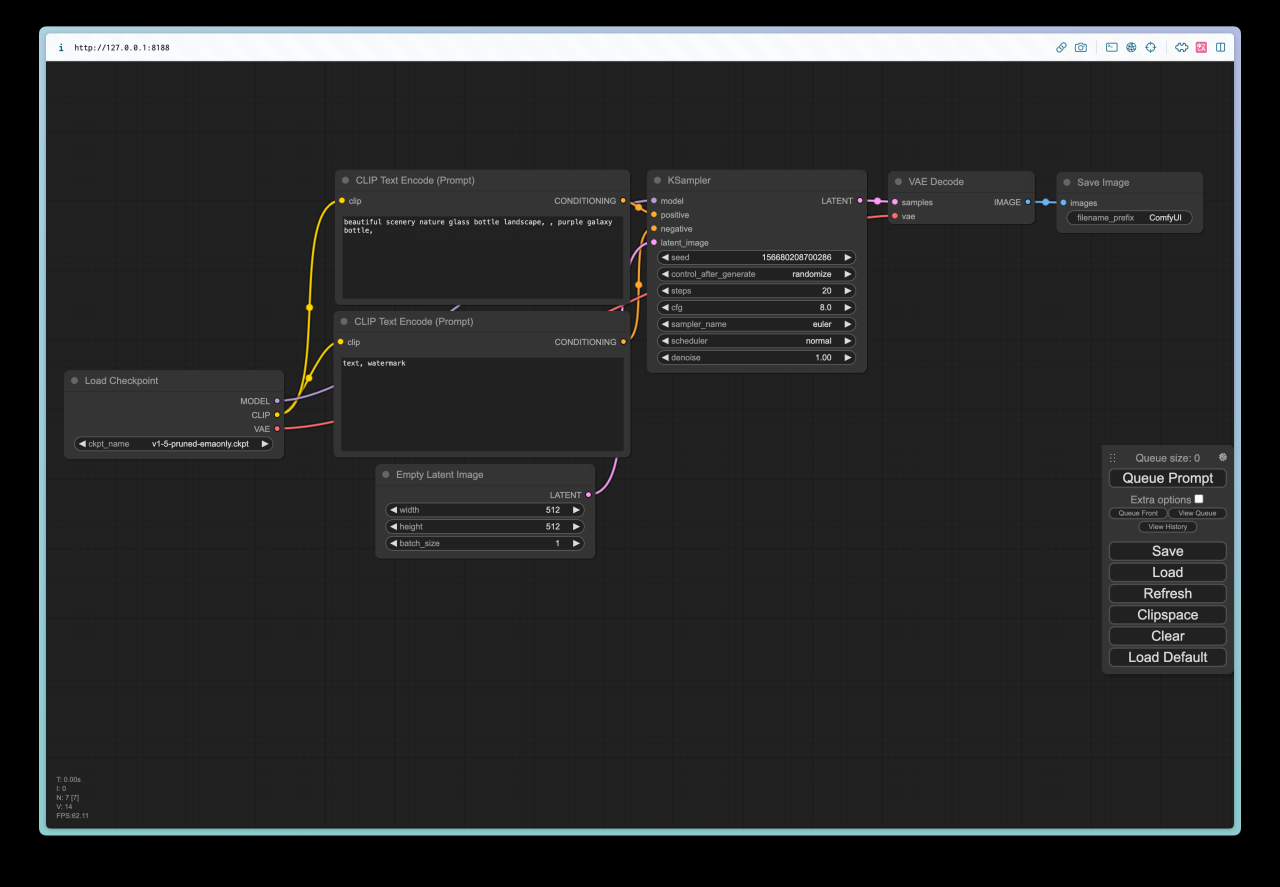
Q&A
Q: 终端显示某个模块下载失败,或无法下载该怎么办?
这是因为网络没有做到终端 FanQiang,终端 FanQiang 需要配置好代理。
# 具体端口要根据自己的 FanQiang 服务来看,最好把这个配置到默认的终端启动项里边export https_proxy=http://127.0.0.1:7890 http_proxy=http://127.0.0.1:7890 all_proxy=socks5://127.0.0.1:7890或者是考虑使用第三方镜像站下载,详细信息请参考对应镜像站的帮助手册。
| 镜像站 | URL | 帮助 |
|---|---|---|
| TUNA | https://pypi.tuna.tsinghua.edu.cn/simple(opens in a new tab) | 🔗(opens in a new tab) |
| 网易 | https://mirrors.163.com/pypi/(opens in a new tab) | 🔗(opens in a new tab) |
| Q: 终端显示 ERROR: Could not find a version that satisfies the requirement pyyaml (from versions: none) 该如何处理? |
此问题来自 Discord 用户 Lulu。
这是因为缺少 pyyaml,你可以运行:
pip install pyyaml完成安装后,再继续安装 ComfyUI。
下载 & 导入模型
安装完 ComfyUI 后,你需要下载对应的模型,并将对应的模型导入到对应的文件夹内。在讲解如何下载模型之前,我们先来简单了解一下 Stable Diffusion 的不同版本之间的差别,你可以根据你自己的需求下载一个合适的版本。
另外,你也可以参考这两篇博客:
不同 Stable Diffusion 的差别
如果你想要了解更多模型,可以查看我们的模型推荐页面:模型推荐。
Stable Diffusion v1.5
- 这是 Stable Diffusion 的的早期版本,目前市场上的很多 Lora 模型以及 ContrlNet 模型都是基于它来构建的,所以在开始使用 ComfyUI 的时候为了少踩坑,建议围绕 1.5 版本进行学习。
- 模型官方介绍:Stable Diffusion v1.x press release(opens in a new tab)
- 下载链接:v1.5 pruned(opens in a new tab)
Stable Diffusion v2.0
- 这是 Stable Diffusion 的一个重大更新,相比于 v1.5 版本,它在图像生成质量和速度上都有所提升。
- 2.0 版本采用了新的文本编码器 OpenCLIP,可以更好地理解文本提示,从而生成更高质量的图像。此外,2.0 版本还支持更高的图像分辨率,可以生成默认分辨率为 512×512 像素和 768×768 像素的图像。
- 模型官方介绍:Stable Diffusion v2 press release(opens in a new tab)
Stable Diffusion XL
- 这是 Stable Diffusion 的最新版本,它在 2.0 版本的基础上进行了进一步的优化和改进。
- XL 版本的主要特点是其更大的模型大小,从 0.98B 扩大到 6.6B 参数,这使得它能够生成更高质量的图像。
- XL 版本还引入了新的功能,如更有艺术感的图像,更真实的图像,以及更清晰可读的字体等。
- 模型官方介绍:Stable Diffusion xl 1.0 press release(opens in a new tab)
- 下载链接:
模型下载
我常用的下载渠道有两个,一个是 HuggingFace,最后一个是 CivitAI 站点。
HuggingFace
你可以将 HuggingFace 理解为 AI 届的 Github。上面会有不少人或组织会将他们的模型分享到上面。你可以通过 HuggingFace 的搜索功能来搜索你想要的模型。
比如我们搜索 Stable Diffusion v1.5,你会看到这样的页面,然后我们点击页面里的 Files and versions 按钮(图中 1),接着你会看到很多文件,此时你需要选择你需要下载的模型文件,然后点击下载按钮(图中 2):
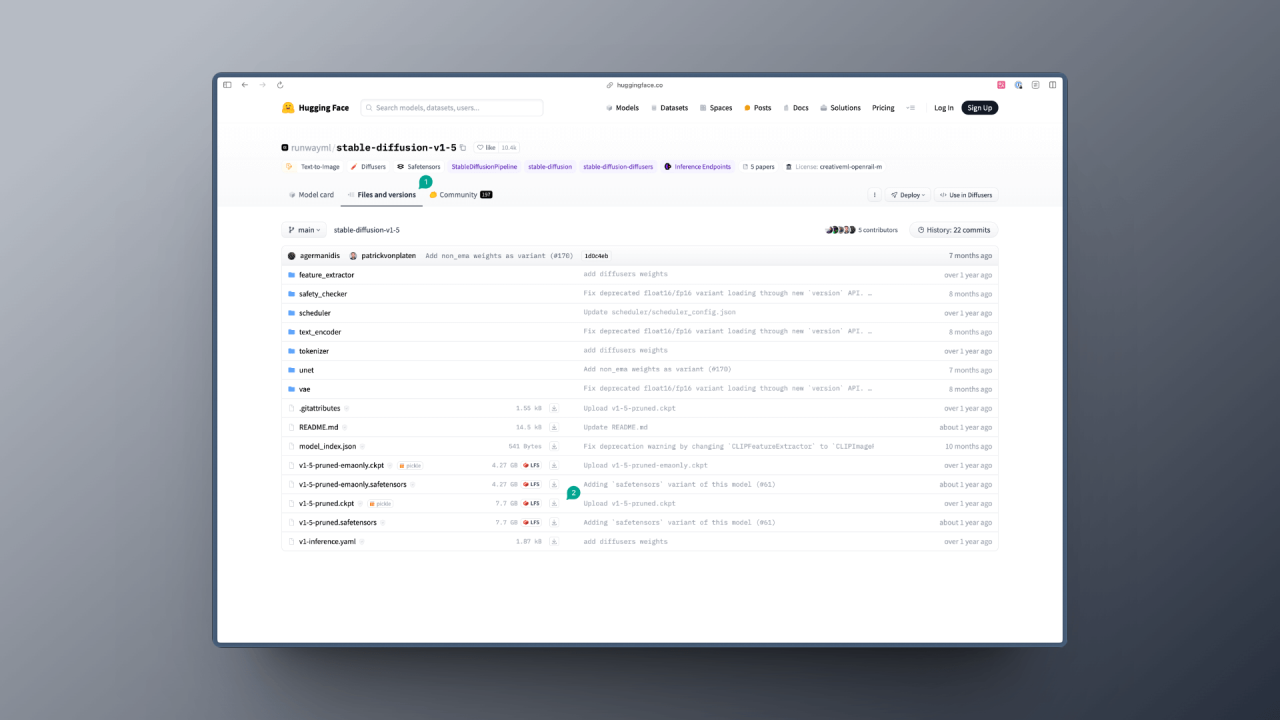
一般你会看到两种后缀的模型:
- safetensors:这种模型一般用的是 numpy 格式保存,这就意味着它只保存了张量数据,没有任何代码,加载这类文件会更安全和更快。
- ckpt:这种文件是序列化过的,这意味着它们可能会包含一些恶意代码,加载这类模型就可能会带来安全风险。
所以在上述的案例中,我会推荐你下载 safetensors 格式的模型。
另外,我建议你在搜索模型的时候,需要看看是不是该模型的官方发的,一般我会看模型的下载数,一般下载数越多的模型,越有可能是官方发的。
CivitAI
与 HuggingFace 不同,CivitAI 站点更偏向于 UGC 一些,所以你会看到更多个人训练的模型,但是这并不意味着它们的质量会差,相反,你会发现有些模型的质量非常好。
而且 CivitAI 比 HuggingFace 多了很多好用的功能,比如你可以通过筛选等方式,看到各种各样优秀的模型:
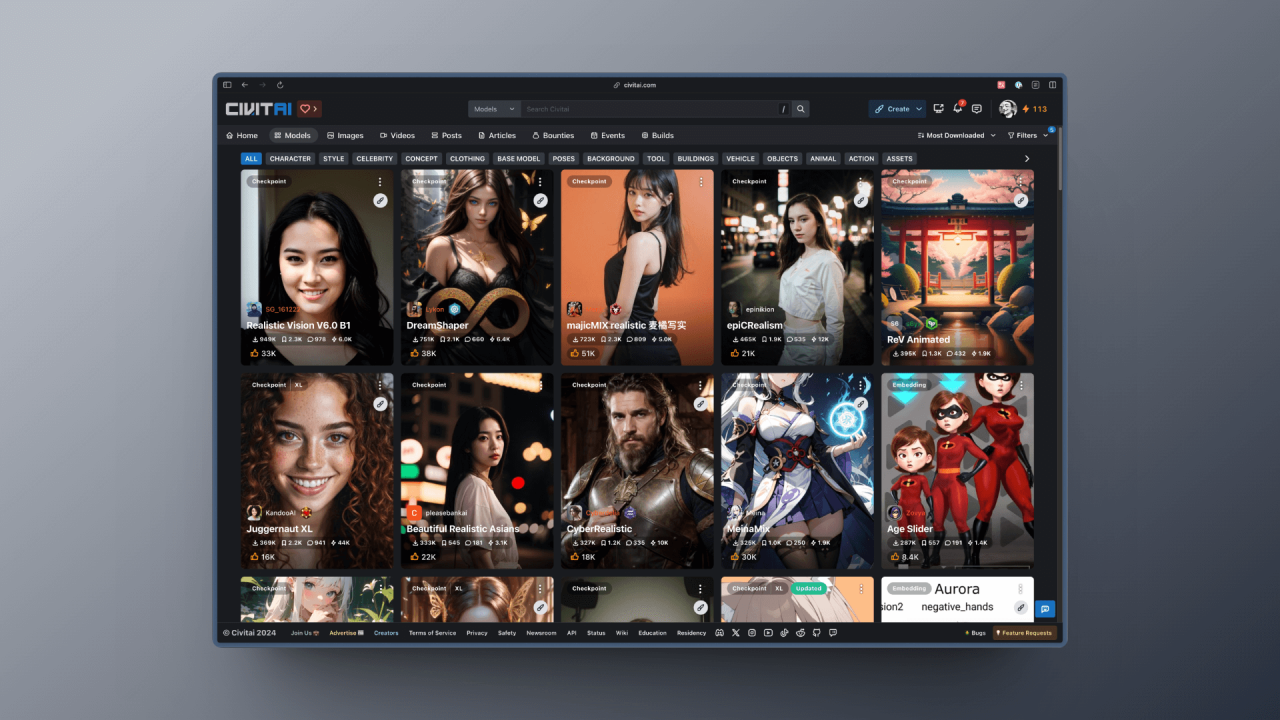
同样的,你也可以通过 CivitAI 的搜索功能来搜索你想要的模型,并下载该模型,以 DreamShaper 为例,你只要点击下载按钮(图中 1)即可下载模型:
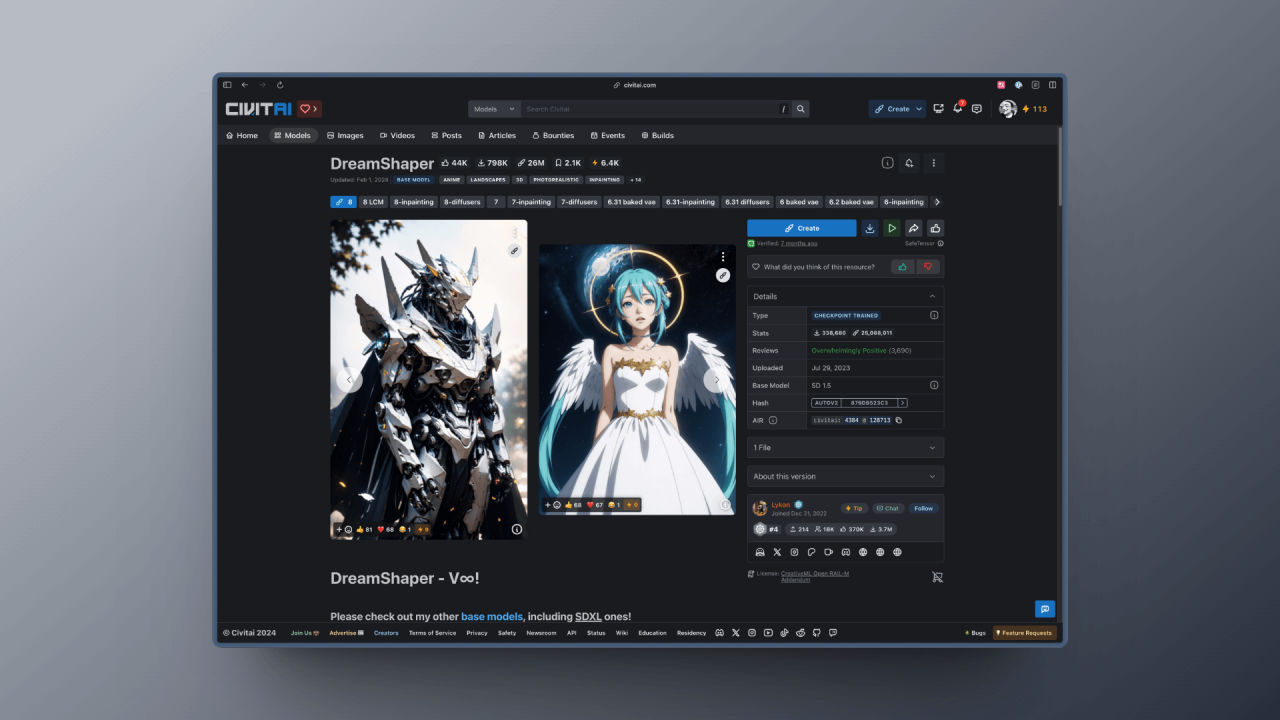
在后续的教程中,我会使用到各种模型,你都可以根据自己的需求在以上两个渠道下载不同的模型。但现在我建议你先在 HuggingFace 上下载 Stable Diffusion v1.5 和 Stable Diffusion XL 模型,前者有很多配套的模型,而后者的出图效果相对比较好,不少最新的模型也都有基于它去优化。
模型导入
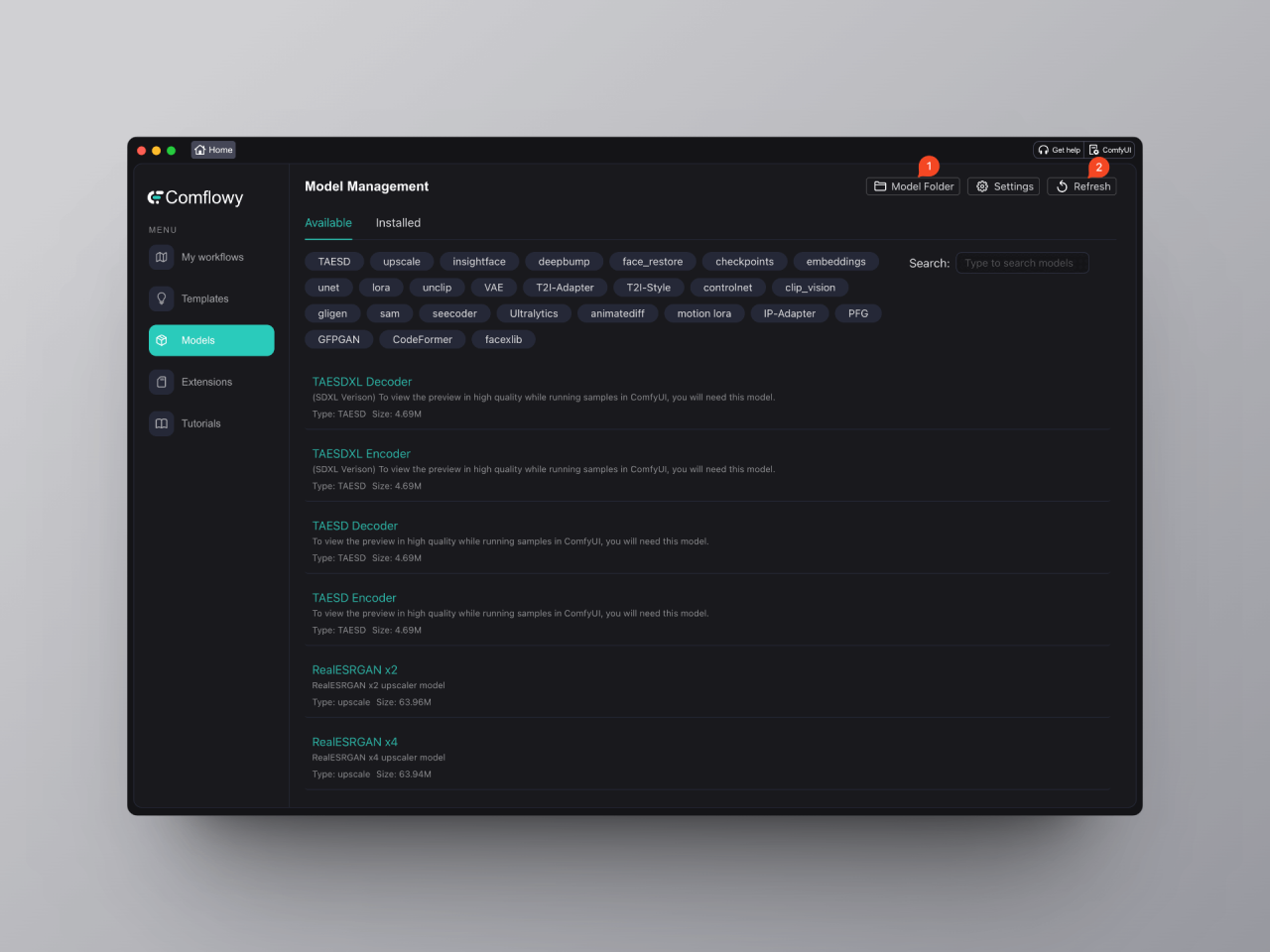
如果你使用的是 ComflowySpace,那么你可以直接在 ComflowySpace 上导入模型。具体的操作步骤如下:
- 切换到 Models 的界面,然后点击右上角的 Model Folder 的按钮(图中①),
- 打开该文件夹后,点击进入里面的 checkpoint 文件夹,将你下载好的模型放入其中。
- 最后再点击一下 Refresh 按钮(图中②)。
🎉 恭喜你,又完成了一个重要的步骤,接下来我们就可以正式进入 ComfyUI 基础篇的学习了。